The Category’s Blind Spot: Dashboard Sophistication Is Not Data Verification
Here is where the market is getting it wrong. Most ESG and carbon reporting platforms — including those recognised as “Leaders” in the 2026 Verdantix Green Quadrant evaluation of enterprise carbon management software — are competing on smarter estimation. Their innovation frontier, as the evaluation itself notes, is machine learning that detects metering gaps and generates statistically robust estimates from historical patterns. Better guesses, applied faster, presented in a cleaner interface.
That is not the same thing as AI-ready data. It is the opposite.
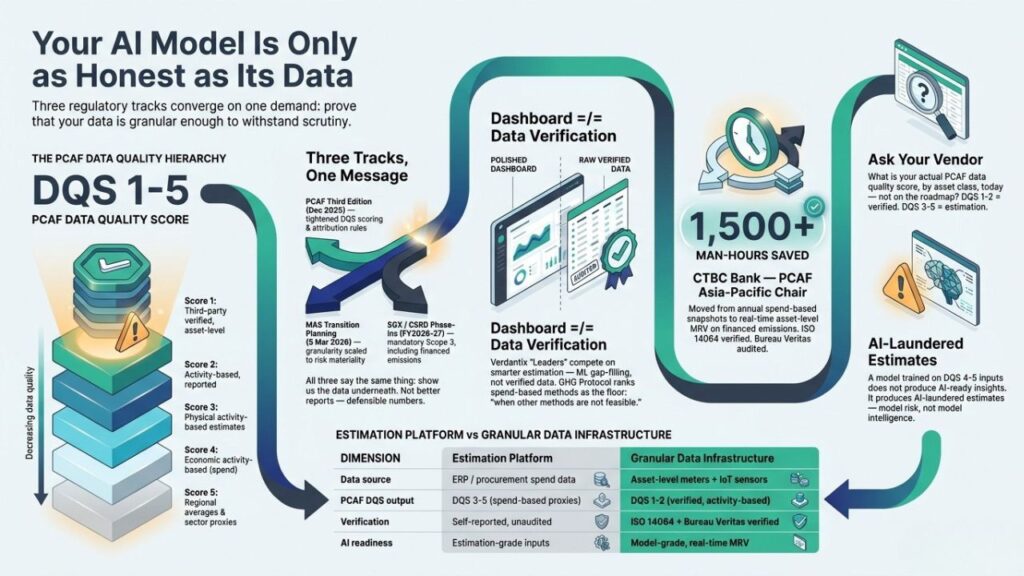
The GHG Protocol’s own Scope 3 Technical Guidance designates spend-based emission factors — the most generic, least granular calculation method available — as the approach to use “when other methods are not feasible.” The floor of the methodology hierarchy, not the standard. PCAF’s data quality framework ranks three options for financed emissions in explicit order of preference: reported and verified emissions first, physical activity-based data second, economic activity-based (spend-based) data last. Options 1 and 2 are preferred over Option 3 “from a data quality perspective” — that is PCAF’s own published language, not an opinion.
Yet spend-based estimation remains what most off-the-shelf platforms default to for most emission categories, because spend data is what already sits in ERP and procurement systems. No new collection effort required. No asset-level measurement. No third-party verification. The incentive structure of the category favours estimation by design, because estimation scales without requiring the hard infrastructure work that AI-ready data actually demands.
The result is a market where an institution shopping for AI-ready data cannot easily distinguish between a tool built on verified, asset-level measurement and one built on well-engineered estimates — because both look the same from a sales presentation. Both claim AI-powered analytics. Both produce PCAF-formatted reports. The difference is what happens when someone asks to see the data quality score underneath.
The One Question That Separates AI-Ready Data from Estimation
The smarter institutions are starting to ask a single, direct question before they evaluate a single feature: what is your actual PCAF data quality score, by asset class, today — not on the roadmap?
That question cuts through everything. A vendor whose architecture produces DQS 1-2 outputs — verified, activity-based, asset-level — can answer it directly. A vendor whose architecture fills estimation gaps with ML-modelled proxies cannot, because the output is structurally a DQS 3-5 number regardless of how sophisticated the interface looks.
This distinction matters most where AI-ready data intersects with model risk. When a credit risk model, a transition finance assessment, or an ESG scoring algorithm trains on financed-emissions data, the quality of that input propagates through every output the model produces. A model trained on DQS 4-5 inputs is not producing AI-ready insights — it is producing AI-laundered estimates. The model’s confidence intervals are a function of the data quality feeding them, and no amount of architectural sophistication at the model layer compensates for structural uncertainty at the data layer.
That is not a compliance problem first. It is a model-risk problem. And it is the reason the AI-ready data conversation is actually a data-verification conversation in disguise.
How Granular Data Infrastructure Changes the Equation
One institution that already made this shift is CTBC Bank — the PCAF Asia-Pacific Chair — which deployed Evercomm’s Nx-Engine to move from annual, spend-based Scope 3 Category 15 snapshots to real-time, asset-level measurement, reporting, and verification. The result: per-line PCAF data quality scoring on financed emissions, replacing estimation with AI-ready data drawn from verified, activity-based sources. The deployment saved over 1,500 man-hours previously consumed by manual data collection and reconciliation.
This is what “Powering AI with facts” looks like as a literal engineering description, not a tagline. The Nx-Engine produces ISO 14064 verified, Bureau Veritas audited outputs — the kind of AI-ready data that survives a credit committee, a regulatory inquiry, or an AI model’s training pipeline, because the verification happened at the data layer before the data ever reached the model.
The architecture matters because it determines what is structurally possible. A platform built around estimation can improve its estimates. A platform built around asset-level measurement and real-time MRV can produce AI-ready data that is verified by design — not estimated and then labelled as verified after the fact. That is the difference between a reporting tool and data infrastructure.
AI-Ready Data as Infrastructure, Not Paperwork
The forward view makes this more urgent, not less. As AI-driven credit models, transition risk assessments, and climate scenario analyses become standard tools in regulated finance, granularity stops being a once-a-year disclosure exercise. It becomes a live input to every model run, every portfolio decision, every stress test.
Institutions that treat AI-ready data as an annual compliance deliverable — something to assemble, submit, and forget — are building their AI systems on a foundation that was never designed to bear that load. The estimation layer was built for disclosure. It was not built for the continuous, high-frequency, model-grade data demands that AI systems impose.\
The institutions that will come through this transition with models that hold up under scrutiny are the ones treating granularity as infrastructure. Not a reporting upgrade. Not a vendor selection checkbox. Infrastructure — the kind that is verified at the source, scored at the asset level, and available in real time, because those are the properties that make data genuinely AI-ready. The distinction between AI-ready data and estimation-grade data is not academic. It is the difference between a model that a regulator can audit and one that unravels the moment someone traces the inputs back to their source.
Research has suggested that large, publicly traded companies — the ones more likely to report verifiable emissions — represent only a fraction of global lending and investment exposure. The majority of borrowers, including SMEs, private companies, and emerging-market entities, generally do not report emissions at all. That structural gap is precisely why most institutions default to estimation: not because they chose it, but because their data architecture left them no alternative. Building AI-ready data infrastructure is how that default changes.
Three regulatory bodies have now said the same thing in three different ways: show us the data underneath. The institutions that can answer that question clearly — with AI-ready data built on verified numbers, not better estimates — are the ones whose AI, and whose credibility, will hold.
The PCAF data quality framework, MAS transition planning guidelines, and GHG Protocol methodology hierarchy all point in the same direction: verified, asset-level data is the standard, not the aspiration. If you want to see what that looks like in practice — at PCAF DQS 1-2, in real-time, on financed emissions — we are happy to show you.